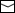メディアとしてのWebの成長を測る
〜サーチロボットを使ったWebコンテンツ統計調査の試み
はじめに
本稿は、国内のWebコンテンツの規模を把握する目的で、郵政研究所と協力して1998年から4年間にわたり実施したWebコンテンツ統計調査の成果をまとめ、分析を加えたものである。世界の多くの人々にとって重要なメディアに成長したWorld Wide Web(WWW)は、その実態を統計的に把握することが困難なメディアであり、特に、情報メディアとしての実力を示すコンテンツ量の規模については、公開されているWebページ総数を示す統計すら存在していない[1]。本研究ではサーチロボットという新しい調査手段を用いてjpドメインのWeb総ページ数の推計を行った。推計結果の妥当性についてはなお検討が必要だが、国内Webの成長の実相を示す貴重な記録が得られたと考えている。なお、筆者は本調査において、調査方法の考案、サーチロボットの基本設計、各回調査の実施と調査結果の集計・分析を担当した。
1 調査の背景
1-1 WWWコンテンツ統計の不備
メディアの実態を表す統計には、提供しているコンテンツ量に関する統計と利用状況の統計があり、主要メディアについてはその両方が整備されている。これらの統計データによって、我々はマスメディアを通じた情報の提供と利用双方の動向を把握し、また情報流通のマクロな状況について定量的に把握・分析することが可能となっている。
しかし、1990年代半ばに登場し、急速にメディアとしての重要性が高まっているWWWについては、その現状や成長の推移を表す客観的な統計データは驚くほど少ない。利用者数や利用時間数等の利用状況については不完全ながらアンケート調査による実態データが存在しているが[2]、情報提供の規模を示す統計、例えばWWWの総ページ数に関する信頼できる統計データは存在していない。インターネットを構成するサーバー数や割り当てドメイン数については時系列的なデータがあるが[3]、これは必ずしも我々が日々接している「膨大な情報の集まり」としてのWWWの規模を表しているわけではない。つまり我々は、WWWのコンテンツ提供の実態を把握する手がかりとしての統計を持っていないのである。
WWWのコンテンツ量を示す統計データが存在しないのには、それなりの理由がある。WWWは分散型システムであり、無数のサーバーで公開されているファイルの所在を一括管理する機能が用意されていない。したがって、WWWのページ総数を知るには、Webページ同士をつないでいるハイパーリンクを辿って、1ページずつカウントしていく必要がある。しかし、現在のWWWは極めて大規模である上、毎日膨大な数のページが新たに追加されているので、リンクを辿って全てのページをカウントすることは事実上不可能である。
それでは、インターネット上で多数提供されているサーチエンジン(検索サイト)を使って、WWWの総ページ数を知ることはできないだろうか。主要なサーチエンジンは、WWWのリンクを自動的に辿って各Webページを調査する「サーチロボット」と呼ばれるシステムを使って、膨大な数のWebページの情報を収集している。しかし、これらのサーチロボットの性能にも限界があり、各サーチエンジンはWWWを構成するページの一部を収録しているに過ぎない。米国NEC研究所のLawrenceとGilesは、1999年2月に行った調査結果から、世界最大のサーチエンジンでもWWW全体の16%しかカバーしておらず、しかもそのカバー率は次第に低下していると推定した[Lawrence & Giles(1999)]。有力なサーチエンジンのデータを見ても、WWW全体の規模を知ることはできないのである。
1-2 過去のWWW規模推計の事例
これまでにもWWWの規模を推計する試みがなかったわけではない。代表的な事例は、前述のLawrenceとGilesによる一連の研究である。彼らは、1997年12月に複数の有力サーチエンジンに重複して収録されているページの割合を調査し、測定した重複率と各サーチエンジンの収録ページ総数をもとに、当時のWWWの総ページ数は3.2億ページ以上あると推定した[Lawrence & Giles(1998)]。また、ほぼ同時期にBharatらも同様の手法で独自に調査を行い、1997年11月時点でのWWWの総ページ数を約2億ページと推定した[Bharat & Broader(1998)]。
Lawrence等の研究は、WWWの総ページ数を初めて客観的データから推計した点で大きな意義があった。しかし、彼等自身が認めているように、この推計には「各サーチエンジンのページ収録状況は相互にまったく独立である」という不自然な仮定が置かれており、推計の精度は低いと見込まれる。
そこで、Lawrence等は、1999年2月には全く異なる方法で総ページ数の推定を行った。彼らは32ビットのIPアドレス空間の中からサンプルアドレスを無作為抽出してWWWサーバーの有無を調べ、見つかったWWWサーバー内のページ数を数えるという方法でWWWの総ページ数を約8億ページと推計した[Lawrence & Giles(1999)]。しかし、この手法でも推計の精度には問題がある。WWWを構成するサーバーの規模は千差万別で、少数の巨大サーバーに多数のページが集中している。このため、調査対象サーバーのサンプル数をかなり大きくとるか、層別抽出の考え方を導入しないと、精度のよい推計はできない。
つまり、過去の推計事例では、WWWのコンテンツ量についてある程度の「当たりをつける」にとどまっており、その精度を確かめるためにも、異なる手法による調査・推計が必要とされているのである。
2 国内Webコンテンツ量の調査と推計
2-1 サーチロボットを応用した調査・推計の考え方
本調査では、WWWの規模を安定的に計測し、その成長を観察するために、サーチロボットを使った新しい調査・推計手法を試みることにした[外薗(1998)]。
一般的なサーチロボットの基本動作は、単純化すれば次のようなものである。
(1) WWW上のあるページにアクセスし、HTMLファイルを取得する。
(2) そのHTMLに書かれているリンク情報を抽出し、リンク先URLを取得する。
(3) 取得したリンク先URLが、自分にとって未発見のURLかどうかを判定する。
(4) 新発見のURLならばそれを次のアクセス先として、アクセスを試みる((1)へ戻る)。
これをひたすら繰り返すことにより、サーチロボットはリンクでつながったWWWのページ全てにアクセスしようとする。ただし、前述したように、WWWの膨大な規模や成長速度を考えると、どれほど高性能なサーチロボットを用意しても、公開されているWWWページに全てアクセスすることは現実には不可能である。そこで、WWWの中の「ある程度の」ページをサーチロボットで調査し、そこで得られるデータをもとにWWWの総ページ数を推計する方法を検討した。この推計を行うには、調査期間内にサーチロボットがアクセスし終わった(または発見した)Webページが、WWWの総ページ数の何パーセントに当たるかを示す指標データを得られればよい。その指標データとして、「既知URLへのリンクの出現率」に着目した。既知URLへのリンク出現率Rkの定義は次のとおりである。
Rk = Nk / N0
ここで N0 :調査中の一定期間にロボットがアクセスしたWebページに記述されていたリンクの総数
Nk :N0のうち、リンク先URLが既に取得済みであったリンクの数
サーチロボットは、新しいWebページにアクセスすると、そのHTML文に記述されているハイパーリンク情報を抽出するが、それらの中には、ロボットにとって未知のURLへのリンクもあれば、過去に既に発見済みもしくはアクセス済みの既知URLへのリンクもある。サーチロボットの調査が進むにつれて、サーチロボットが既に知っているURLの数は増えていくので、アクセス先のWebページで既知URLへのリンクが見つかる確率Rkは次第に高くなっていく。そして、サーチロボットが全てのWebページのURLを取得し終わった時には、アクセスしたページで見つかるリンク先は100%既知URLとなる。したがって、サーチロボットがある程度の数のURLを取得した段階で、新たに発見するリンクについてのRkを調べれば、それまでに取得したURLがWWW全体の何パーセントに当たるかが推定でき、全てのページにアクセスしなくてもWWWの総ページ数を推計できることになる。
ここで、ひとつ注意すべきことがある。Webページ間のリンクがWWW全体にランダムに、かつ偏りなく張られていれば、既知URL数とRkは比例し、サーチロボットの調査が進むにつれてRkは直線的に上昇する。しかし、実際のWWWではリンクの分布に大きな偏りがあり、一部の「有名」ページに多数のリンクが集中している。このような有名ページは、早期にサーチロボットに発見される確率が高く、また、いったん発見されるとRkの値を一気に高めることになる。したがって、実際の調査では、Rkの値は直線的に上昇するのではなく、図1のように初期に急激に上昇し、その後漸増していく形になると予想される。
2-2 調査・推計結果から見た国内Webコンテンツの規模
以上の考え方に基づいて、我々は独自の統計調査用サーチロボット「Loki」を開発し、jpドメイン内のWeb総ページ数を推計するための調査を実施した[4]。
Lokiの基本動作は、一般的なサーチロボットと同じである。Loki特有の機能として、新たなリンクが見つかる度に飛び先URLが既知のものかどうかを判定し、一定時間毎に、新しく発見したリンクのうち何パーセントが既知URLへのリンクだったか(各時点でのRkの値)を集計し、報告する。
Lokiを使った調査は1998年2月から半年毎に実施し、2002年春まで合計9回実施した(表1)。調査の出発点は、国内Webサイトへの大規模なリンク集ページに設定した。Webの成長に合わせて調査の規模を拡大し、表1に示すように収集URL数は回を追うごとに増加した。調査日数は回によって異なるが、後述する総ページ数推計に必要な量のデータを収集するために、Rkの値が60〜63%に達することを調査終了の目安とした[5]。
| 調査期間 | 発見サーバー数 | 発見ファイル数 | 訪問ファイル数 | |
|---|---|---|---|---|
| 第1回 | 1998年2月10日〜2月26日 | 34,874 | 3,856,718 | 1,242,533 |
| 第2回 | 1998年8月3日〜9月7日 | 54,808 | 10,004,358 | 3,875,982 |
| 第3回 | 1999年2月16日〜3月11日 | 64,329 | 11,580,431 | 2,236,797 |
| 第4回 | 1999年8月4日〜9月26日 | 82,470 | 18,994,821 | 8,281,030 |
| 第5回 | 2000年1月17日〜3月7日 | 95,252 | 21,575,245 | 10,072,691 |
| 第6回 | 2000年8月30日〜9月27日 | 114830 | 23,281,351 | 10,432,758 |
| 第7回 | 2001年2月10日〜3月19日 | 151,672 | 32,657,395 | 15,767,910 |
| 第8回 | 2001年7月20日〜10月30日 | 176,714 | 32,005,868 | 15,141,464 |
| 第9回 | 2002年2月3日〜4月23日 | 197,252 | 36,873,029 | 17,617,925 |
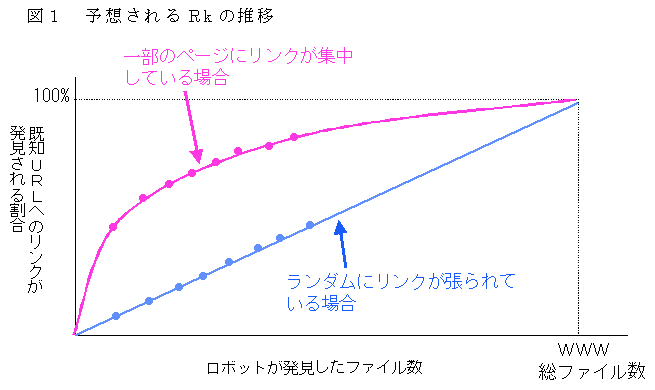
図2は、各回の調査におけるRkの推移を1日毎(2002年2月調査についてのみ2日毎)にプロットしたものである。予想どおり、調査開始後しばらくは急激に上昇し、その後漸増するパターンを示している。回を追うごとにグラフ全体が右側へ広がっているが、これはjpドメインWebの規模が次第に拡大したことを示している。そして、各回のグラフの形を見ると、漸増へ移った後は多少の揺らぎはあるものの、ほぼ一定のペースでRkが高まっている。そこで、この部分を最小二乗法で直線近似して延長し、Rkが100%となる点の横軸の値を各調査時点でのWeb総ファイル数の推計値とした。ただし、ここで推計した総ファイル数には画像ファイルなどWebを構成する全てのファイルが含まれるので、推計した総ファイル数にHTMLファイルの構成比を乗じたものが各調査時点でのWeb総ページ数となる。
こうして推計したjpドメインのWebの総ページ数の推移を図3に示す。推計結果によれば、jpドメインWebの総ページ数は1998年2月時点では約1000万ページだったが、1999年2月時点で約2900万ページ、2002年2月では約6600万ページに拡大した。初期には1年間で約3倍に拡大していたが、最近では成長が鈍化し、ほとんど止まりかけている。

Webを構成するファイルの所在をセカンドレベルドメイン(ac、co等)別に分類すると、ほぼ一貫してacドメイン(大学・研究機関のWebサイト)のファイル数の構成比が縮小し、代わってed(学校等)、gr(各種団体)、ne(プロバイダ等)ドメインの割合が拡大している(図4)。最近では2001年に認められた汎用ドメイン(ac,co等の区別をつけないドメイン)のファイルが急速に増加していることも確かめられた。

Lokiはアクセスした各ファイルのデータ量の情報も取得している。この情報から、jpドメインのWebを構成するファイルの総データ量を推計すると、1998年2月時点では約300ギガバイト、2002年2月時点では約5テラバイトとなった(図5)。総データ量の伸び率は総ページ数の伸び率よりも大きく、総ページ数や総ファイル数の伸びに見られるような鈍化傾向もあまり見られない。

データ量の推移をファイルの種別に比較すると、PDFファイルのデータ量の増加が著しい。PDFは、WWWの主流であるHTMLと異なり、テキストとグラフィック類をまとめて収録できるファイル形式である。この調査を始めた1998年当時はほとんど存在していなかったが、HTMLよりも作成が容易であるため利用が急速に広まったことが、推計結果から読み取れる。
2-3 推計結果の妥当性の検討
前節で見たように、サーチロボットを使った調査によって、過去4年間のjpドメインWebの拡大の様子を捉えることができた。しかし、ここで得られた推計結果の妥当性については、「正解」が誰にも分からない以上、他の手法で得られた推計結果と比較対照して検討することしかできない。
jpドメインのWeb総ページ数を調査・推計した事例は極めて少ないが、Lawrence等の手法を踏襲した日本語Webページ総数推計を水谷正大等が発表している[来生他(1999)、水谷他(2001)]。水谷等の推計結果は、1999年11月で1億2000万ページ以上、2000年10月で2億5600万ページと、本調査の推計結果に比べかなり大きな値となっている。水谷等の調査方法では、jpドメイン以外の日本語ページも調査・推計の対象となるが、その違いを考慮してもなお大きな差異があると言わざるを得ない。その原因として、以下の理由により、水谷等の推計結果が過大推計になっていることが考えられる。
Lawrence等の手法では、複数のサーチエンジンの収録ページ数と、収録ページの重複率をもとにWWW総ページ数を推計する。この重複率を測定するために、いくつかのキーワードを各サーチエンジンに入力して、検索結果の突合せを行う。ところが、最近のサーチエンジンでは、あるキーワードを入力し検索しても、そのキーワードを含むページ全てを検索結果として表示しなくなっている。あまりに多くのページが検索結果として表示されると利用者の利便を損なうため、それぞれの基準でふるいにかけ、検索結果を絞り込んでいるのである。その結果、見かけ上、収録ページの重複率が実際よりもかなり低く見えることになる。水谷等はこの効果を考慮せず、各サーチエンジン間の「見かけ上の」重複率をもとに推計しているため、結果的にWeb総ページ数を過大に見積もっていると考えられる。
では、国内の有力サーチエンジンの収録URL数はどうなっているだろうか。例えば、Infoseek Japanを運営していたデジタルガレージは、1997年8月に日本語Webページの収録URL数が588万URLであると発表した[デジタルガレージ(1997)]。また、NTT-Xが提供しているサーチエンジンGooでは、1998年10月には日本国内の収録URL数を約1700万、2000年1月には約3500万、2002年8月には約6300万とアナウンスしていた[NTT-X(2002)]。Infoseek JapanやGooが公表した収録URL数は、同時期のLokiを使った推計値に近い。これらのサーチエンジンはjpドメイン以外の日本語ページも収録対象としているものの、我々の推計値が正しいならば、国内サーチエンジンのページ収録率はかなり高いということになる。これは、Lawrence等が指摘した傾向と相反している。しかし、WWW全体の中で日本語Webページは1割以下を占めるに過ぎず、残りの大部分が英語ページであると推定されるのに対し、国内有力サーチエンジンのサーチロボットの性能は十分高いと考えられるので、国内サーチエンジンの日本語ページ収録率が米国のサーチエンジンの英語ページ収録率よりも高くなるのは、むしろ当然のことと言える。
Lawrence等は、残念ながらドメイン別のWebページ数は算出していない。そこで、ホストコンピュータ数のドメイン別構成比を使って、jpドメインWebページ数の見込み値を計算し、今回の推計結果と比較してみた。Internet Software Consortiumの1999年7月の調査によれば、世界のインターネット接続ホストのうち、jpドメインの構成比は3.7%である[Internet Software Consortium(1999)]。Lawrenceが推計した1999年2月の世界のWWW総ページ数8億ページにこの構成比を乗じると、jpドメインのWebページ数は3000万ページ程度ある計算になる。一方、同時期のLokiによる調査から推計したjpドメインのWebページ数は約2900万ページである。大雑把な比較ではあるが、まったく異なる手法で推計した結果がよく一致していることからも、我々の推計結果は実態とそれほど外れていないと考えられる。
2-4 他メディアとの規模の比較
それでは、本調査で推計したjpドメインWebのコンテンツ規模は、他のマスメディアと比較してどのように評価できるだろうか。WWWは音声や動画も含むマルチメディア媒体だが、基本となるのは文字情報であり、「ページ」という概念もあるため、出版メディアとの比較が分かりやすい。
本調査の推計結果によれば、1998年2月から2002年2月までの4年間に、jpドメインWebの総ページ数は約5500万ページ増加した。これを、Webの新規提供コンテンツと見なす。一方、代表的な出版メディアである新聞の過去4年間の発行ページ数は、約4100万ページである [6]。また、雑誌については年間発行ページ数の統計がないが、出版科学研究所が発表している雑誌の発行点数と年間発行回数、平均ページ数から、4年間で約5000万ページ程度の発行量があったと推定できる[7]。一方、1ページ当たりの文字数は、新聞が約10000文字、雑誌が2000文字程度であるのに対し、WebはHTMLの平均データ量から、2500文字程度と推定される[8]。これらの値を総合すると、4年間に新たに提供されたWebの情報量は、同時期に発行された雑誌原稿の総情報量と同程度かやや多く、新聞原稿の総情報量の1/3から1/4程度の規模であったと推定される[9]。
3. 個人ホームページ数の推計
WWWの大きな特徴として、誰もが情報発信者になれるメディアであることが挙げられる。実際、WWWを利用すれば、数多くの個人ホームページに行き当たる。しかし、公開されている個人ホームページがどれくらいの数に上るのかは、全く統計がなく、推測することすら難しい。
個人ホームページで最も一般的なのは、プロバイダが加入者用に提供するサーバースペースを使って個人が開設したWebサイト(個人サイト)だが、プロバイダによってne、co、orなど様々なドメインの場合がある。また、企業サイト(coドメイン)や各種団体サイト(or,grなど)、大学サイト(acドメイン)の中でも、そのメンバーの個人ページが公開されている場合がある。このように、個人ホームページは多くのドメインにまたがって分布しており、ドメインで識別することができないため、全体像を把握することが困難なのである。
そこで、ドメインではなくWebページに書かれている内容から個人ホームページを識別し、その総量を推計することを試みた。Webページの頻出単語の中から個人ホームページ特有の言葉(識別キーワード)を見つけ出し、その出現状況を調べることにより、Web全体に占める個人ホームページの割合を推計するというのが基本的な考え方である。
調査は、大きく2つの段階に分けて実施した。まず、2000年5月に、次の手順でカテゴリー別のHTMLの収集と識別キーワードの抽出、キーワード出現率[10]の測定を行った。
(1) 公開されているリンク集等をもとに、個人サイト、企業サイト、学校サイト、自治体サイトと分かっているWebサイト各1000サイトのリストを作成した。[11]
(2) リストアップしたサイトを対象に、サーチロボットでそれらのサイトに含まれるHTMLファイルを収集した。
(3) 形態素解析を行い、収集したHTMLに含まれている単語を抽出し、その出現率を集計した。
(4) 各カテゴリーにおける単語の出現率を比較して、あるカテゴリーのサイトでのみ出現率が高い言葉(識別キーワード)を抽出した。
次いで同年9月に実施した第2段階の調査では、jpドメインWeb全体での平均的な単語出現率を知るために、jpドメインのWebサーバーからランダムに10000サーバーをサンプリングし、サーチロボットでそれらのサーバーに含まれるHTMLを収集して、第1段階で抽出した識別キーワードの出現率を計測した。
抽出した識別キーワードと、各カテゴリーのサイトおよびランダムサンプリングしたサイトでの出現率を表2に示す。
| 識別キーワード | ランダム抽出した サイトでの出現率 |
企業サイト での出現率 |
個人サイト での出現率 |
自治体サイト での出現率 |
学校サイト での出現率 |
|
|---|---|---|---|---|---|---|
| B | A1 | A2 | A3 | A4 | ||
| 企業 | 01.株式会社 | 4.72% | 13.47% | 1.23% | 1.40% | 0.33% |
| 02.代表取締役 | 0.50% | 3.20% | 0.05% | 0.06% | 0.05% | |
| 03.当社 | 1.35% | 6.96% | 0.27% | 0.06% | 0.00% | |
| 04.資本金 | 0.42% | 2.81% | 0.04% | 0.15% | 0.01% | |
| 05.当社 | 0.94% | 2.48% | 0.05% | 0.01% | 0.00% | |
| 個人 | 06.日記 | 2.83% | 0.53% | 7.47% | 1.51% | 1.00% |
| 07.ファン | 3.54% | 1.30% | 9.50% | 0.92% | 0.47% | |
| 08.チャット | 0.92% | 0.05% | 3.70% | 0.03% | 0.24% | |
| 09.管理人 | 0.79% | 0.11% | 2.51% | 0.15% | 0.03% | |
| 10.ランキング | 1.67% | 0.13% | 5.15% | 0.13% | 0.06% | |
| 11.ごめん | 1.14% | 0.03% | 2.72% | 0.12% | 0.60% | |
| 自治体 | 12.役場 | 0.27% | 0.20% | 0.27% | 12.76% | 0.48% |
| 13.特産 | 0.28% | 0.55% | 0.16% | 11.10% | 0.24% | |
| 14.広報 | 1.13% | 1.44% | 0.39% | 10.92% | 1.43% | |
| 15.人口 | 0.76% | 0.69% | 0.55% | 6.86% | 0.74% | |
| 16.町長 | 0.14% | 0.06% | 0.04% | 5.67% | 0.18% | |
| 17.市長 | 0.41% | 0.64% | 0.20% | 3.56% | 0.33% | |
| 学校 | 18.本校 | 0.20% | 0.03% | 0.01% | 0.10% | 14.55% |
| 19.校長 | 0.26% | 0.11% | 0.16% | 0.46% | 9.50% | |
| 20.学年 | 0.63% | 0.13% | 0.55% | 0.45% | 13.02% | |
| 21.校歌 | 0.06% | 0.00% | 0.00% | 0.07% | 5.70% |
企業サイトや学校サイト、自治体サイトでは「いかにも」という感じの言葉が識別キーワードとして並んでいるが、個人サイトの識別キーワードにはあまりキーワードらしくない言葉が見られる。また、個人サイトの識別キーワードは、個人サイトでの出現率もあまり高くない。これは、個人サイトが扱っているテーマが非常に雑多であり、定型的な要素が少ないことを示している。
次に個人ホームページの構成比の推計だが、以下の考え方で推計を行った。ランダムサンプリングしたサイトでの単語出現率Bは、ほぼウェブ全体での単語出現率を表していると考えられるので、各カテゴリーでの単語出現率A1〜A4を説明変数として、次の式で表すことができるはずである。
B = X1A1 + X2A2 + X3A3 + X4A4 + (1-X1-X2-X3-X4)C
ここで、 Xn:n番目のカテゴリーのページ構成比
An:n番目のカテゴリーの単語出現率
C:その他のページでの単語出現率
そこで、Bを説明変数、A1〜A4を説明変数として重回帰分析を行い、Bを最もよく再現するX1〜X4を求めれば、これがほぼjpドメインWebにおける各カテゴリーのWebページの構成比に該当すると考えられる。
重回帰分析の結果を表3に示す。重回帰係数=各カテゴリーのページ構成比と見なし、2000年9月時点のjpドメイン総ページ数の推計値5600万ページを乗じると、個人ホームページは1900万ページ前後、企業ホームページ1600万ページ前後と推計される(図6)。個人ホームページはjpドメインのWebページの約1/3を占め、企業サイトのページ総数よりも若干多いという結果が得られた。
| 係数 | 標準誤差 | t | P-値 | 下限95% | 上限95% | |
|---|---|---|---|---|---|---|
| 企業 | 0.282 | 0.019 | 14.719 | 0.000 | 0.242 | 0.322 |
| 個人 | 0.334 | 0.022 | 15.408 | 0.000 | 0.288 | 0.379 |
| 自治体 | 0.026 | 0.014 | 1.863 | 0.080 | -0.003 | 0.054 |
| 学校 | 0.021 | 0.013 | 1.539 | 0.142 | -0.008 | 0.049 |
| 回帰統計 | |
|---|---|
| 重相関R | 0.973 |
| 重決定R2 | 0.947 |
| 補正R2 | 0.879 |
| 標準誤差 | 0.003 |
| 観測数 | 21 |

さらに、ランダムサンプリングしたサーバーをセカンドレベルドメイン別に分類し、各ドメイン内での識別キーワードの出現率を被説明変数に置いて重回帰分析を行えば、個人ホームページのセカンドレベルドメイン別の分布を推計することができる。その分析結果を図7に示す。個人ホームページは、co、ne、orドメインに広く分布しており、企業・学校・自治体サイトの分布とは明らかに異なっていることが分かる。

4. まとめと今後の課題
サーチロボットを活用した調査により、jpドメインWebの総ページ数の推計、個人ホームページ数の推計を行った。その結果、jpドメインのWeb総ページ数は2002年2月頃には約6600万ページであること、その成長は最近になって鈍化していること、コンテンツの提供規模は雑誌に比肩できる規模に達していること、個人ホームページが全体の約1/3を占めていること等が明らかになった。これらの推計により、情報メディアとしてのWebが提供しているコンテンツの実態を量的に明らかにすることができたと考えている。
しかし、この調査・推計には多くの課題も残っている。まず、サーチロボットを使った調査では、調査・推計対象に含まれないWebページが存在する。例えば、キーワード入力等によって都度生成されるページ、管理者がサーチロボットのアクセスを拒否する設定をしているページ、アクセスにパスワード入力が必要なページ等である。調査・推計の対象となるのは、一般に公開され、ハイパーリンクを辿ることで到達できる「indexable」なページに限られる。ただし、同様の制約は多くのサーチエンジンや、そのサーチエンジンを使ったWWW総ページ数推計にも当てはまる。Lawrence等の研究でも推計の対象はindexableページであり、WWWの規模の議論は、indexableページの総数を対象としていることが多い。
もう一つの大きな課題は、jpドメイン以外の日本語ページが調査・推計対象から外れていることである。最近、.comや.net等のドメインを持つ日本語Webサイトが増加しており、これらの日本語Webサイトも含めた調査・推計手法の開発が急務となっている。
2002年度からは、これらの課題に対応するため、調査システムを一新することになっている。従来よりも大規模なシステムを用いて徹底した調査を行うことにより、推計精度を高めるだけでなく、より詳細な国内Webの実態を示すデータが得られると期待している。
注:
[1] World Wide Webはその名の通りグローバルなメディアである。本稿では、その全体を指す言葉として「WWW」を用い、WWWの一部、特に日本国内で提供される部分を示す場合は「Web」という言葉を用いる。また、WWWを構成する各ページのことを「Webページ」と表記する。
[2] 例えば、財団法人インターネット協会が毎年発行している『インターネット白書』には利用実態に関するデータが収録されている。
[3] 例えば、日本レジストリサービスのWebサイト
http://jpinfo.jp/stats/allocated_domains.html 等
[4] 調査対象をjpドメインに限定したのは、WWW全体を対象とすると必要な情報収集に時間がかかりすぎることが最大の理由である。WWWの成長・更新速度は極めて速いため、調査に数ヶ月以上かかると状況が変化してしまい、調査結果そのものに意味がなくなってしまう恐れがある。
[5] 初回調査はRkが60%に至る前に調査を打ち切ったため、他の回に比べ推計結果の信頼性が劣る。第8回、第9回調査は、インターネットのトラフィック急増の影響で調査に3ヶ月前後を要したが、この時期は、Webの成長速度が低下していたため、調査期間長期化の影響は小さいと考える。
[6] 電通広告統計による。
[7] 雑誌の平均ページ数については適切なデータが見つからなかったため、300ページと想定して推計した。
[8] 新聞・雑誌の1ページあたり文字数については、総務省(旧郵政省)の「情報流通センサス」における設定値を参考にした。
[9] 本調査ではウェブページの更新周期を調べていないため、ここではWebページの純増分の情報量だけを新聞・雑誌と比較したが、本来はページ更新分の情報量も加える必要がある。
[10] 本稿での「キーワード出現率」とは、「母集団に含まれるWebページのうち、あるキーワードが1回以上登場するWebページの割合」を意味している。
[11] リスト作成に用いたリンク集は、学校については大阪教育大のリンク集、自治体については地方自治情報センターの「NIPPON-Net」である。個人、企業については、全体をカバーするリンク集がないため、規模の大きい複数のリンク集を用いた。
参考文献:
(1) Steve Lawrence, C.Lee Giles, Searching the World Wide Web, SCIENCE
Vol.280, p98 (1998)
(2) Steve Lawrence, C.Lee Giles, Accessibility of information on the web,
NATURE Vol.400, p107 (1999)
(3) Krishna Bharat, Andrei Broder, A technique for measuring the relative
size and overlap of public Web search engines, the 7th International World
Wide Web Conference, April 1998
(4) 外薗博文、「日本のインターネット(WWW)の現状」、郵政研究所月報 No120, p79 (1998)
(5) 来住伸子、大森貴博、笹塚清二、近藤晶子、水谷正大、小川貴英、「統計的推定による日本語Webの調査」、インターネットコンファレンス'99、1999年12月
(6) 水谷正大、大森貴博、来住伸子、小川貴英、「検索エンジンを利用した日本語Webページ数の統計的推定の研究」、東京情報大学論文集 Vol.5
No.1 (2001)
(7) デジタルガレージ(Infoseek Japan),
http://ftp.infoseek.co.jp/release/0804isjPV100.html, 1997年8月
(8) NTT-X, http://www.goo.ne.jp/help/door/, 2002年8月
(9) Internet Software Consortium,
http://www.isc.org/ds/WWW-9907/dist-byname.html, 1999
(10) 電通総研、『情報メディア白書2002』
(11) 全国出版協会出版科学研究所、『出版指標年報』各年版
(12) 郵政大臣官房企画課、『情報流通センサスに関する調査研究報告書』、1989年9月
「マス・コミュニケーション研究 No.62」に掲載
 03-3261-7431
03-3261-7431